
The default installation of MongoDB is standalone, that is fine for development and testing purposes. However if you find yourself in the position of having a production-like MongoDB in standalone set up (maybe for a very small app that grew up) and you want to convert this into a Replica Set installation to benefit from the automatic replication and failover, then you are stuck!!!
There is no way as today (version 2.2.3) to migrate a standalone
installation into a Replica Set configuration without downtime! In
fact the procedure documented in the official MongoDB website
(here)
says that first thing you need to do is to shut down your database
server and restart with the --replSet option.
Frankly I don’t understand why the replica set “mode” is not the default. You could start with only one node in a default configuration and then just add nodes as you need.
Anyway, if you have to restart the database, then let’s hope that the restart with a simple configuration option doesn’t take long… wrong!
In this post there is the procedure that I crafted from my own experience and a good dose of google-ing. The objective is to restart the database server as quickly as possible so that the maintenance window will be of few seconds, and the applications will reconnect automatically to the database.
However there are a number of “gotchas” that you need to be aware before you actually proceed.
The impatient hackers can skip the whole explanation and jump to the procedure at the bottom of the post. However if you are interested to understand what is happening when you start the MongoDB in replica set mode for the first time just read below.
OplogSize #
Once you restart your database with the
replSet
option your database is not usable until you perform the replica set
initialization with rs.initiate() from the mongo console.
rs.initiate() will then create the OpLog (a capped collection) to
store every operation that perform a change on your dataset. The size
of the OpLog is defined by default as 5% of your free space (for a
Linux 64-bit system). So if your development machine has 150GB of free
space it will create 4 files of 2GB each. But if your production
machine has 2TB of free space (very common for a mid-range dedicated
server) you will end up over 100GB of OpLog files.
Now rs.initiate() make sure that the right amount of space is
provisioned before accepting requests, in this case even in a good
machine you might have to wait quite a long time, in fact it creates a
number of 2GB zero-filled files until it reaches the OpLog desired
space. On a good machine it can take up to 15-20 sec per file, so if
you have to create 50+ of them you will have to wait 15 mins or more.
How to estimate your optimal oplogSize. #
In reality you might not need all that space, and probably you can run just fine with lot less Operational Log. This can be configured by the oplogSize configuration option as size in MB. Estimating how much space you need is a good mix of black magic and luck, also because once set it cannot be “easily” changed (see here). It requires a good knowledge of your application to forecast, but if you have already an application running you can take advantage of monitoring tools and backups. The way I measured my required capacity was to use the daily backups. For example if the average difference between two consecutive (uncompressed) daily backups is 1.5GB you can deduce that this is the amount of NEW data in one day. But what about deletes and updates? In facts deletes and updates must be accounted separately.
Here is where the knowledge of the application plays its role. However monitoring tools such as Ganglia that keep tracks of database operations can come handy on evaluating the proportions between inserts, updates and deletes. In my application inserts are largely predominant as I use a event sourced architecture so I can easily say that 90% are inserts, 10% update and deletes. Therefore by making a simple proportion I get the following figure:
- 1.5Gb : 90% = X : 100% –> X = 1.66GB
More commonly an application that modify the state has proportions that looks more like 20% inserts, 70% updates and 10% deletes. After you figure out how much space you need for one day worth of work. Then you need to think what is the max time on which one of your replica set member can be down before re-synch. For example if you wish to have at least a two weeks buffer then get to:
- 1.66GB * 14 days ~= 24GB
Therefore you need to set oplogSize = 24576 (24 * 1024). Upon
rs.initiate() command, MongoDB is going to try to pre-allocate 12
files of 2GB each zero filled called local.0 to local.11. This
time consuming operation can be prepared ahead saving lot of time
(later we’ll see how).
Last thing important to remember is that every node in the replica set that might become a primary will need this space available reserved. Therefore make sure that the oplogSize is available on every node.
Authentication #
In order to authenticate members of a replica set, and encryption key must be provided. Be aware that this encryption is used only for the credentials transmissions but not for the data. So if your replica set span across unprotected network you need to set up a VPN or SSL tunnel solution. The encryption key must be generated prior the start up or the MongoDB server and distributed to all nodes.
Never have a Replica Set of 2 nodes -> very bad! #
There are a number of problems in distributed computing that simply cannot be solved with only two nodes. The most popular is the split brain in which a distributed system affected by a network partition for which two nodes can’t communicate between each other but both of them can communicate with the rest of the world.
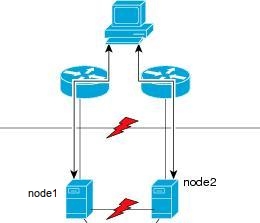
In this case both nodes will think that the other nodes is dead and
decide to become the Primary. The Primary is the node that accept
write operations such as insert(), update(), and remove(),
Secondary nodes accepts only read.
In MongoDB this problem is solved by the use of a voting system. If the Primary goes down, the remaining nodes will vote to elect a new Primary keeping in consideration freshness of replicated dataset and node priority. The primary needs to reach the quorum of votes (half + 1). If there are only two nodes the quorum is still 2 votes required (2 / 2 + 1 = 2). So if you have a replica set in MongoDB with only two nodes, one Primary and one Secondary and for any reason you take down any of the two members, even the secondary, the Primary will detect that he doesn’t have the majority any more and it will demote itself to a secondary. At this point you will not be able to write to your database at all!!!
This is somehow unexpected by developers and might get you unprepared; see this blog post for example.
To avoid this situation have a minimum of 3 nodes or set up an Arbiter.
The procedure #
At this point we can see the steps required in order to change your standalone MongoDB into a Replica set
NOTE: those steps are for a CentOS installation, if you run on Debian/Ubuntu the process name, configuration files, directories, user and group ownership are slightly different.
- First edit the mongo configuration file
/etc/mongod.confand add or edit the following settings:
# this is the replica set name
# every node will need to have the same name
replSet = setname
# this is the authetication encryption key
# this will be required to be same on every node
keyFile = /etc/mongodb.key
# This is the operational log size
# here we assume ~24GB for example
oplogSize = 24000
# optionally - create a separate directory per DB
directoryperdb = true- then create a keyFile
# generate the key and make it readable only by mongo server
sudo openssl rand -base64 753 > /etc/mongodb.key
sudo chown mongod:mongod /etc/mongodb.key
sudo chmod 0600 /etc/mongodb.key- (reminder) use the same replSet for every node
- (reminder) copy the key on every node
now we have to generate the local.n files, for an oplogSize of 24GB we will create a 12 files of 2GB and we will initialise them with zeros. Eventually this set of files will replace (if present) the current local.n files that you have. However you must not overwrite them if the server is running, therefore we will create them with a slightly different name and then replace them when is time. Make sure that you create them in the same physical and logical device of your DB files to avoid a device to device copy at swap time.
cd /var/lib/mongo/local
# as root user
for i in {0..11}
do
echo "Initializing new-local.$i"
dd if=/dev/zero of=new-local.$i bs=2146435072 count=1
chown mongod:mongod new-local.$i
chmod 0600 new-local.$i
done- at this point we can restart the mongodb server and swap the files
# stopping the server
sudo /etc/init.d/mongod stop
# now replace local.n files
cd /var/lib/mongo/local
sudo rm -fr local.*
sudo rename 's/new-local/local/g' new-local.*
# restarting the server
sudo /etc/init.d/mongod start-
when the startup process is completed and the mongodb logs show the following message:
[rsStart] replSet info you may need to run replSetInitiate – rs.initiate() in the shell – if that is not already done
then you can issue the initiate command with:
$ mongo admin --port 27017 -u admin_user -p admin_pass --eval 'rs.initiate()'The rs.initiate() command should last few seconds and your database
will be back and available. Now your MongoDB is a fully functioning
Primary instance of a replica set. At this point you can add new nodes
with rs.add( "host:port" ) and if you are planning to put only two
nodes remember that you HAVE TO set up an Arbiter.
Sources:
- https://docs.mongodb.org/manual/tutorial/convert-standalone-to-replica-set/
- https://docs.mongodb.org/manual/tutorial/change-oplog-size/
- https://docs.mongodb.org/manual/tutorial/deploy-replica-set/
- https://tebros.com/2010/11/mongodb-arbiters-with-only-two-replicas/
- https://groups.google.com/forum/?fromgroups=#!topic/mongodb-user/Ix3BqdG-ogs
- https://engineering.foursquare.com/2011/05/24/fun-with-mongodb-replica-sets/
- https://blog.serverdensity.com/notes-from-a-production-mongodb-deployment/